Scaling in Transformer Architectures: The Mathematical Rationale behind $\sqrt{d_k}$
In the architecture of Transformers, the self-attention mechanism is defined by the Scaled Dot-Product Attention. While the dot product measures the similarity between Query () and Key () vectors, the division by is not a heuristic convenience but a critical stabilization required for numerical optimization.
This paper formalizes the relationship between vector dimensionality, variance explosion, and the subsequent saturation of the softmax function.
1. The Variance of High-Dimensional Dot Products
Consider two vectors, a Query and a Key , both of dimension . The dot product is defined as:
Under standard initialization weights (e.g., Xavier or Kaiming initialization), we assume that the components and are independent random variables with a mean of zero and a variance of one:
1.1 Mathematical Derivation
The variance of the product of two independent random variables and with zero mean is:
Since the components of the vectors are independent, the variance of their sum (the dot product) is the sum of their variances:
Conclusion: As the dimensionality increases, the variance of the dot product grows linearly with . For modern models where or , the resulting values often fall into extreme ranges (e.g., ).
2. The Softmax Saturation Problem
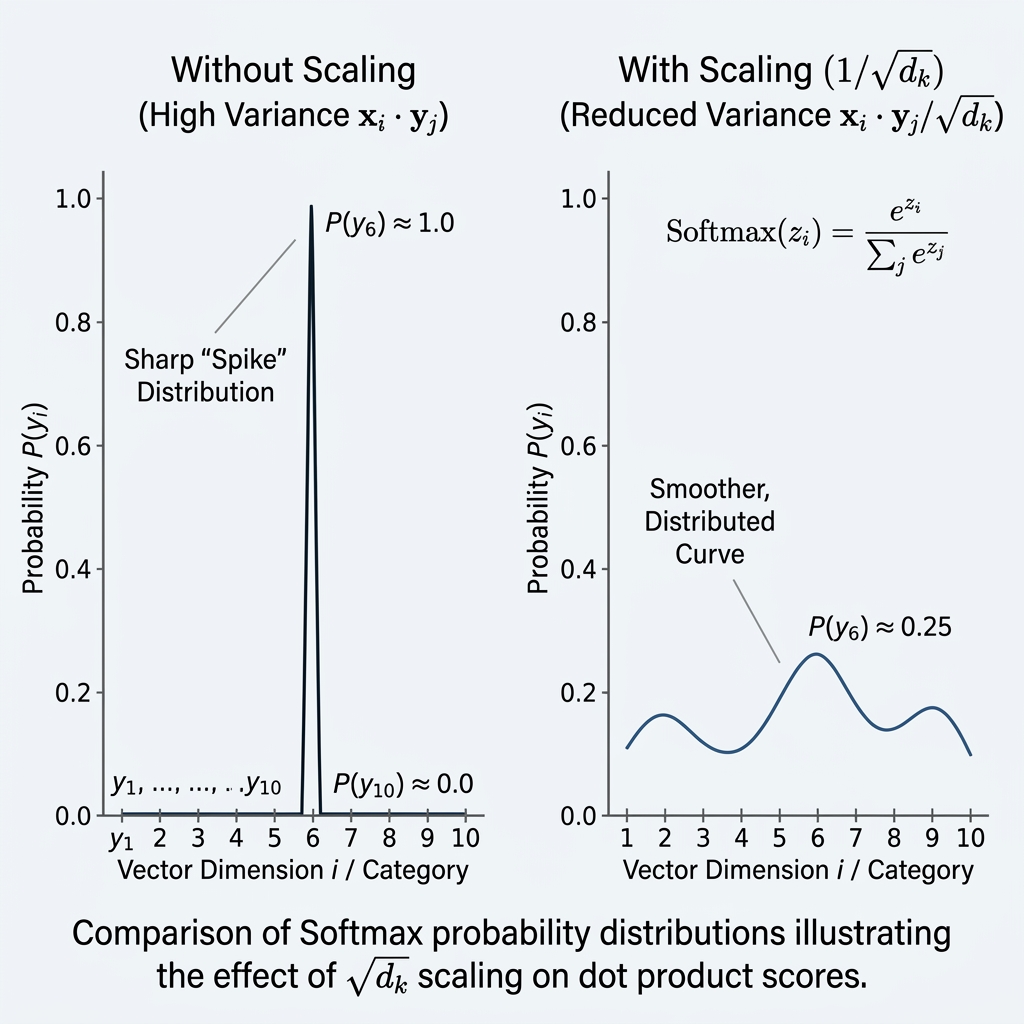
The output of the dot product is passed into the softmax function to translate similarity scores into a probability distribution:
The softmax function's behavior is dictated by the relative differences between its inputs. When the variance of the input is large, the values diverge exponentially.
2.1 Gradient Vanishing
If the scores are large, the softmax function "saturates," producing a distribution that approaches a one-hot vector. In this saturated state, the local gradients of the softmax function become extremely small:
- When is large, .
During backpropagation, these near-zero gradients effectively halt the updates to the weight matrices and , leading to the Vanishing Gradient problem and preventing the model from converging.
3. Stabilization via Scaling
To maintain the sensitivity of the softmax function, we must ensure that the variance of the input to the softmax remains independent of the dimension .
By applying a scaling factor of , we utilize the property of variance :
This normalization ensures that the input to the softmax is roughly unit variance regardless of how large the model’s internal hidden dimensions grow.
4. Performance Comparison
| Attribute | Unscaled Dot-Product | Scaled Dot-Product () |
|---|---|---|
| Input Variance | (High) | (Controlled) |
| Softmax State | Saturated (Approaching One-Hot) | Smooth / Distributed |
| Gradient Flow | Vanishing (Near Zero) | Robust / Healthy |
| Training Stability | Poor / High Risk of Divergence | High / Faster Convergence |
[!IMPORTANT] Key Research Insight: Scaling the dot product is the primary mechanism that allows Transformers to utilize extremely high-dimensional latent spaces. Without this term, increasing the depth and width of a Transformer would lead to immediate failure in gradient propagation.