Understanding the Context Window: The Short-Term Memory of LLMs
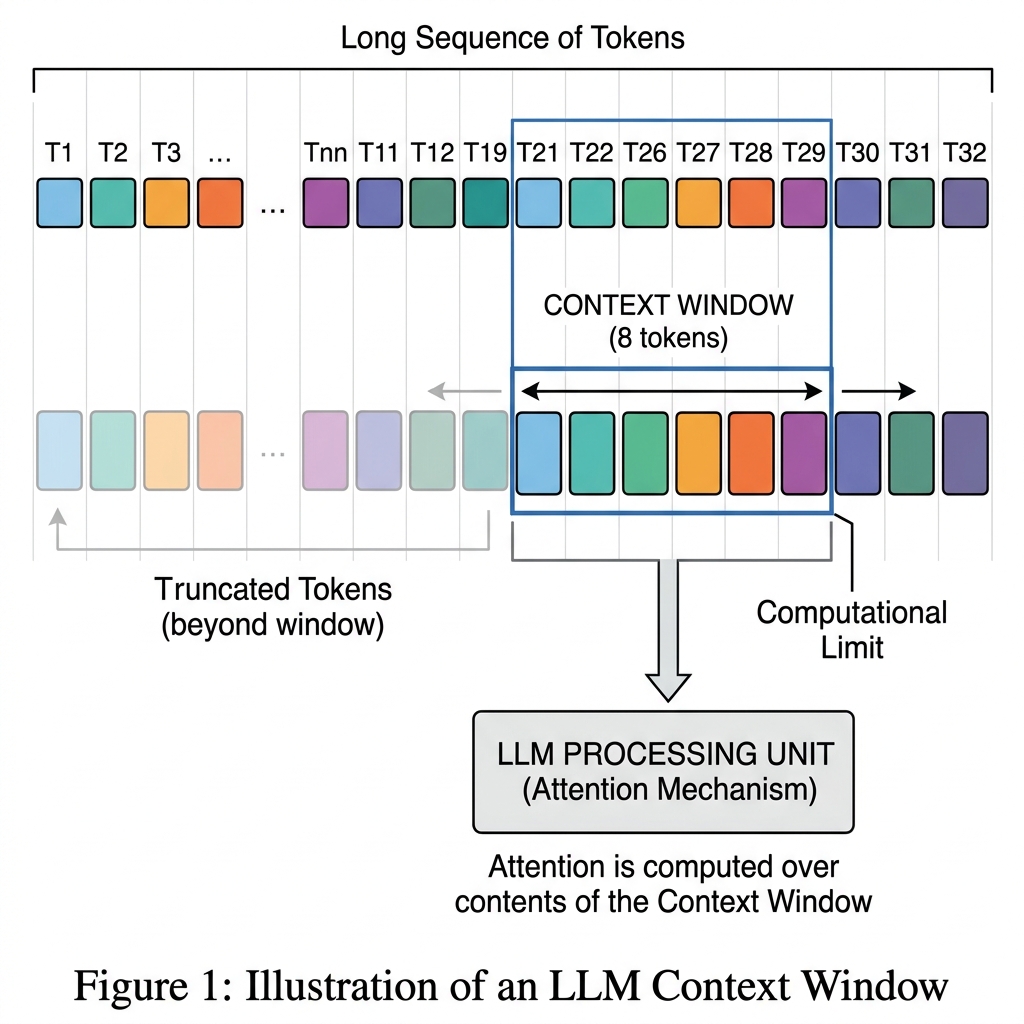
The context window in a Large Language Model (LLM) is the maximum amount of text (measured in tokens) that the model can process, read, and remember at any single moment.
To use an analogy, imagine the context window as the model’s short-term memory or the size of its reading desk. If you hand the model a document that fits on the desk, it can read the whole thing and answer questions about it. If the document is too large and falls off the edge of the desk, the model simply cannot see or remember those missing pages.
Here is a detailed breakdown of how it works and why it is one of the most critical specifications of an LLM.
1. How It Works (Tokens, Not Words)
Context windows are measured in tokens, which are chunks of words, syllables, or characters. A general rule of thumb for English is that 1 token ≈ 0.75 words.
Crucially, the context window is a shared budget between your input (the prompt) and the model's output (the generated response).
- Input Tokens + Output Tokens ≤ Context Window Limit.
- If you have a model with an 8,000-token context window and you feed it a 7,000-token article, it only has 1,000 tokens left to generate a summary or answer your questions.
2. Why the Context Window Matters
A. Document Processing and Summarization Older models had small context windows (e.g., 2,048 tokens or roughly 3 pages of text). If you wanted them to summarize a 50-page financial report, you had to artificially chop the report into tiny pieces, summarize each piece, and then summarize the summaries. Today, models with large context windows (ranging from 128,000 to over 1 million tokens) can ingest entire books, codebases, or hours of transcribed audio in a single prompt and connect the dots across chapters.
B. Conversational Continuity When you chat with an AI, it doesn't inherently "remember" what you said 10 minutes ago. Every time you send a new message, the chat application resends the entire chat history to the model so it can understand the current context. If your conversation exceeds the context window, the system must drop the oldest messages. When this happens, the AI suddenly "forgets" things you discussed earlier in the chat.
C. In-Context Learning (Few-Shot Prompting) LLMs perform much better when you give them examples of how you want them to behave. If you want the AI to format data into a highly specific JSON structure, you might provide 5 or 10 examples in your prompt. A larger context window allows you to pack in more instructions, rules, reference data, and examples, guiding the model to a highly accurate output without needing to fine-tune its underlying weights.
D. Retrieval-Augmented Generation (RAG) In enterprise applications, LLMs are often connected to company databases. When a user asks a question, a search engine finds the most relevant documents and pastes them into the LLM's prompt so it can read them and answer. A larger context window allows the system to retrieve and inject more documents at once, improving the chances that the AI has the right information to answer accurately and reducing AI hallucinations.
3. Why Can't We Just Make Them Infinite?
If bigger is better, why don't all models have an infinite context window? The answer lies in computer science and hardware limitations:
- The Quadratic Cost of Attention: Standard Transformer architecture uses the Self-Attention mechanism (where every token looks at every other token). If you double the context window, the computational power and memory required roughly quadruples ( complexity).
- VRAM Limitations: Holding massive amounts of context requires a huge amount of VRAM (Video RAM) on the GPUs running the model.
- The "Lost in the Middle" Phenomenon: Even if a model has a 1-million-token context window, it doesn't mean its recall is perfect. Research shows that many LLMs suffer from a "lost in the middle" effect—they are excellent at remembering information at the very beginning and the very end of a massive prompt, but struggle to retrieve facts buried in the middle of the text.