Strategic Informatics: A Formal Investigation into Undersampling Mechanisms for Imbalanced Classification
While oversampling techniques like SMOTE augment the minority class, Undersampling serves as an indispensable counter-strategy by strategically reducing the majority class distribution. In large-scale datasets—such as those encountered in Network Intrusion Detection System (NIDS) research—undersampling is critical for managing computational complexity and preventing the classifier from being overwhelmed by the majority distribution. This paper formalizes the primary algorithmic approaches to undersampling.
1. Stochastic Selection: Random Undersampling
The most primitive form of undersampling involves the non-heuristic, stochastic removal of majority samples. To achieve a perfectly balanced distribution, we select a subset of samples equal to .
The probability of any given majority sample being included in the final training partition is:
Risk Analysis: While computationally efficient, Random Undersampling suffers from Information Loss. By discarding potentially informative majority samples, the model may fail to capture the full variance of the "Normal" class, leading to a diminished Decision Boundary.
2. Proximity-Based Heuristics: The NearMiss Suite
To mitigate the randomness of sample removal, the NearMiss family of algorithms utilizes -Nearest Neighbors (-NN) to retain majority samples that are "informative" based on their proximity to the minority class.
NearMiss-1: Boundary Proximity
Retains majority samples that have the minimum average distance to the nearest minority samples. Goal: Select majority points that are closest to the minority region (boundary focus).
NearMiss-2: Global Proximity
Retains majority samples that have the minimum average distance to the farthest minority samples. Goal: Select majority points that are centrally located within the minority manifold's global span.
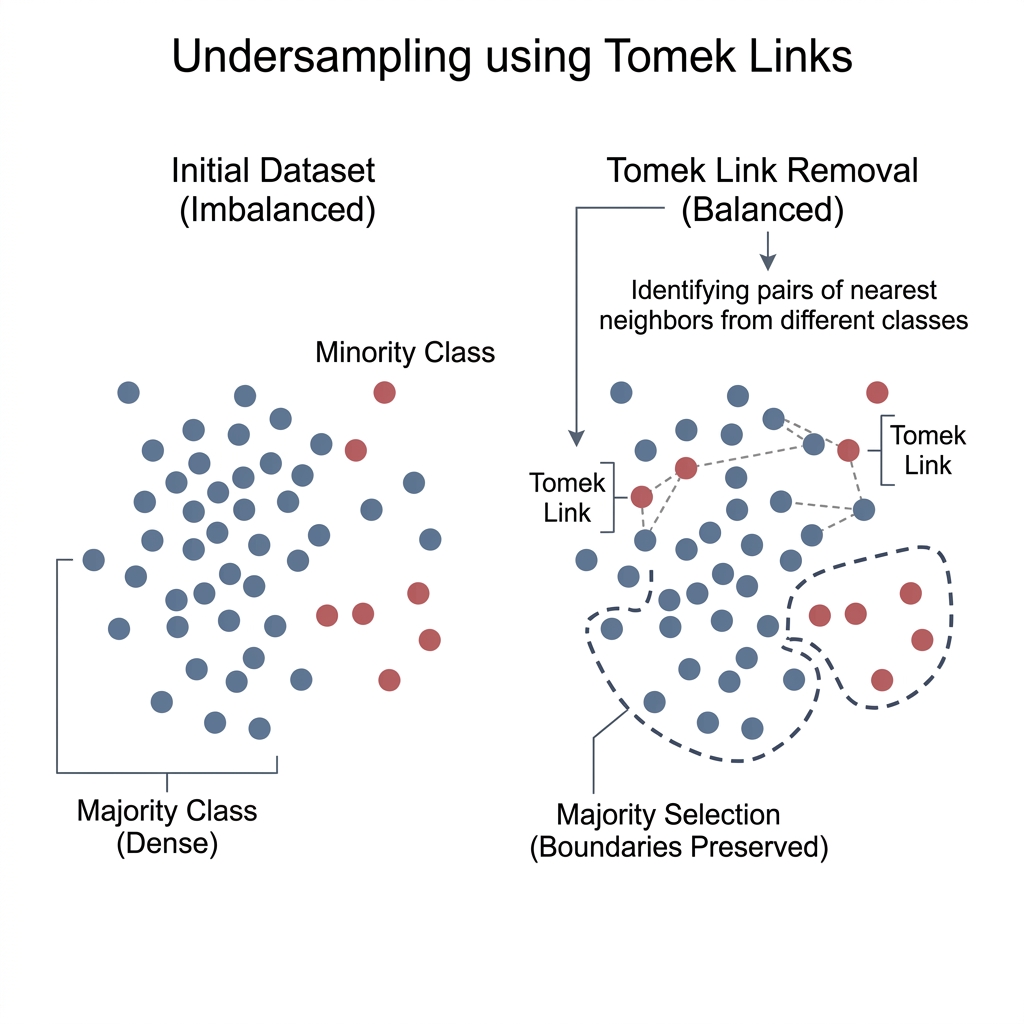
3. Boundary Cleaning: Tomek Links
Tomek Links represent a more sophisticated, "cleaning" approach to undersampling. A pair of samples from different classes—where and —is defined as a Tomek Link if they are each other's nearest neighbors.
Formally, is a Tomek Link if:
Resolution Strategy: By removing the majority sample in every Tomek Link pair, we effectively increase the "margin" between classes. This process reduces overlap and clarifies the Decision Boundary for architectures like CNNs or LSTMs, which are sensitive to local noise.
4. Hybrid Strategies and Case Optimization
In high-stakes domains like the Moore Network Traffic Dataset, a singular approach often suffices poorly. Instead, a Hybrid Pipeline is recommended:
- Denoising: Apply Tomek Links to remove contradictory majority samples at the boundary.
- Augmentation: Apply SMOTE to synthesize high-variance minority samples.
- Balancing: Apply Random Undersampling to align the final class counts.
| Metric | SMOTE (Oversampling) | Undersampling |
|---|---|---|
| Data Integrity | Synthetic generation. | Empirical removal. |
| Computational Cost | High (Increased ). | Low (Reduced ). |
| Principal Risk | Overfitting (Noise synthesis). | Underfitting (Information loss). |
| Primary Use Case | Sparse minority distributions. | Massive majority distributions (Big Data). |
5. Architectural Conclusion
Undersampling is not merely a method of data reduction, but a strategic tool for Informative Sampling. By leveraging NearMiss heuristics or Tomek Link cleaning, practitioners can ensure that the model remains computationally efficient while focusing its learning capacity on the most discriminative regions of the feature space.
[!TIP] Implementation Note: When using
imbalanced-learn, versioning is critical.NearMiss(version=1)focuses on local boundary points, which is generally superior for complex, non-linear boundaries in network security datasets.