Taxonomy of Machine Learning Optimization: A Survey of Training Paradigms
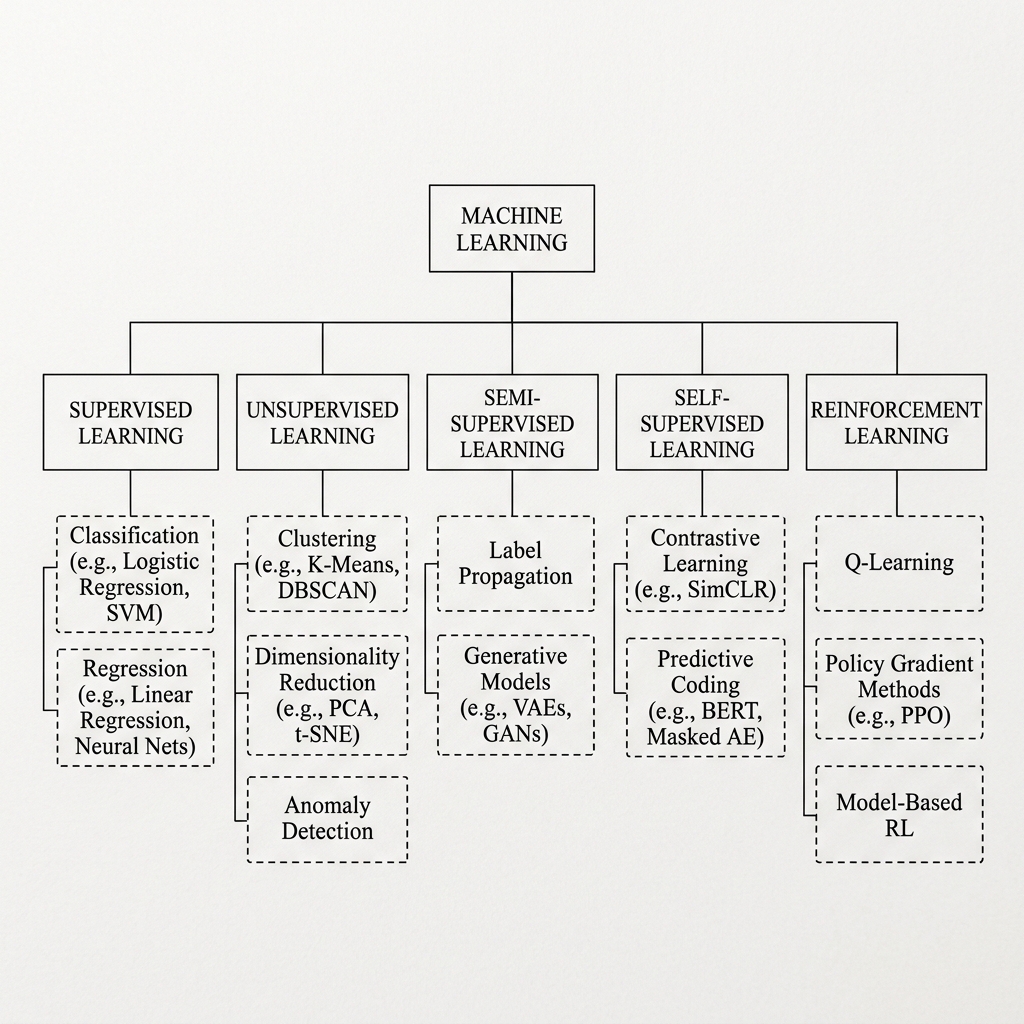
The selection of an optimization paradigm in Machine Learning (ML) and Deep Learning (DL) is mathematically dependent on three deterministic variables: the topology of the input space , the availability of ground-truth labels , and the systemic objective function.
This paper provides a formal classification of the primary training methodologies, evaluating their inductive biases and operational constraints.
1. Supervised Learning: Deterministic Mapping
Supervised Learning constitutes the "Teacher-Student" optimization framework. The model objective is to approximate a mapping function from a dataset of empirical pairs .
Mathematical Objective
Given a loss function , the optimization goal is the minimization of empirical risk:
Common Metrics:
- Cross-Entropy (Classification):
- Mean Squared Error (Regression):
2. Unsupervised Learning: Structural Inference
In the Unsupervised paradigm, the model operates on an unlabeled space . The objective is the discovery of latent structures, probability densities, or internal correlations within the manifold.
Core Methodologies
- Clustering: Partitioning into disjoint subsets by minimizing intra-cluster variance.
- Dimensionality Reduction: Projecting high-dimensional tensors onto a lower-dimensional subspace while preserving variance (e.g., PCA) or topological distance.
- Latent Feature Extraction: Utilizing Autoencoders to minimize reconstruction error: .
3. Semi-Supervised and Hybrid Approaches
This methodology addresses the sparsity of labeled data by utilizing a minor subset of labels in conjunction with a dominant unlabeled set .
- Pseudo-Labeling: Iterative refinement where a model generates self-labels for high-confidence samples in .
- Consistency Regularization: Enforcing prediction stability under stochastic perturbations of the input manifold.
4. Self-Supervised Learning (SSL): Structural Autoproduction
SSL has become the foundational engine for Transformer-based architectures. It derives supervision directly from the intrinsic structure of the input data, effectively transforming Unsupervised data into a Supervised task.
- Autoregressive modeling: Predicting given context .
- Denoising Autoencoders: Reconstructing original signals from corrupted/masked inputs.
- Contrastive Learning: Maximizing mutual information between multiple views of the same data point while minimizing it across different samples.
5. Reinforcement Learning (RL): Sequential Policy Optimization
RL facilitates the learning of optimal policies through dynamic interaction within a Markov Decision Process (MDP).
The Bellman Equation
The fundamental governing equation for updating action-value estimates (Q-values) is:
Where:
- : Instantaneous reward.
- : Discount factor for temporal utility.
- : Learning rate.
6. Scientific Summary Matrix
| Paradigm | Label Status | Optimization Objective | Primary Domain |
|---|---|---|---|
| Supervised | Explicit | Error Minimization | Prediction / Regression |
| Unsupervised | Null | Structural Discovery | Clustering / Generation |
| Semi-Supervised | Sparse | Hybrid Refinement | Expert-scarce domains |
| Self-Supervised | Implicit | Feature Representation | Foundation Models (LLMs) |
| Reinforcement | Dynamic Reward | Expected Value Maximization | Control / Game Theory |
[!NOTE] Research Insight: The convergence of these paradigms—specifically the integration of Self-Supervised pre-training followed by Supervised fine-tuning or Reinforcement Learning from Human Feedback (RLHF)—currently represents the state-of-the-art in general-purpose intelligence.