Synthesizing Minority Samples: A Formal Analysis of Linear Interpolation in Imbalanced Classification
In supervised learning, class imbalance presents a significant topological challenge, often biasing classifiers toward the majority distribution. The Synthetic Minority Over-sampling Technique (SMOTE) addresses this by transcending simple replication (Random Oversampling) and instead performing linear interpolation in the feature space. This paper formalizes the mechanics of SMOTE and its impact on the structural geometry of minority class clusters.
1. Mathematical Formalism of Synthetic Generation
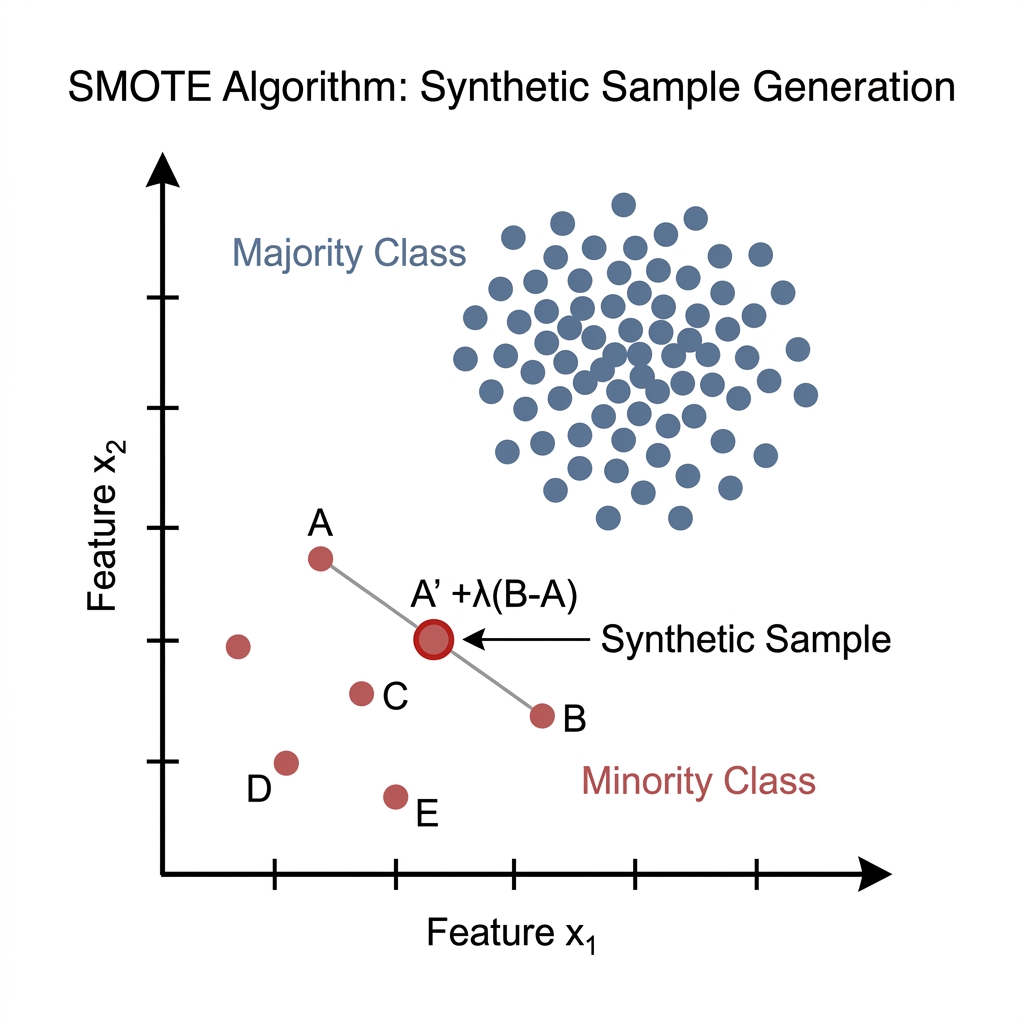
The SMOTE algorithm operates by augmenting the minority class through the generation of synthetic samples along the line segments connecting existing minority samples and their -nearest neighbors.
Step 1: Neighborhood Selection
For each minority sample , the algorithm identifies a set of nearest neighbors within the same minority class. Proximity is typically determined using the Euclidean distance metric:
Step 2: Linear Interpolation
A specific neighbor is randomly selected from the -nearest set. The synthetic sample is then computed by interpolating between the anchor point and the selected neighbor :
Where (the "gap") is a random scalar sampled from a uniform distribution:
This operation ensures that the vector difference is scaled by a random factor, effectively placing the new sample at a stochastic position on the segment .
2. Geometric Interpretation: Decision Boundary Expansion
The fundamental advantage of SMOTE over Random Oversampling lies in its ability to increase the topological diversity of the minority class.
| Feature | Random Oversampling | SMOTE |
|---|---|---|
| Mechanism | Exact duplication of minority samples. | Linear interpolation between neighbors. |
| Topological Effect | Increases density at existing locales (high risk of overfitting). | Expands the convex hull and decision boundaries. |
| Statistical Diversity | Zero; maintains original variance. | High; introduces new, plausible observations. |
By populating the space between existing samples, SMOTE forces the classifier to learn a larger, more generalized region for the minority class, rather than memorizing individual points.
3. Numerical Validation: Feature Space Mapping
Consider a network traffic analysis scenario where we evaluate Packet Size () and Duration ().
- Anchor Point ():
- Selected Neighbor ():
The Difference Vector is calculated as:
Applying a randomly sampled :
The resultant synthetic sample maintains the structural characteristics of the minority class while introducing numerical variance necessary for robust model convergence.
4. Topological Hazards and Performance Constraints
Despite its utility, SMOTE is sensitive to the underlying data distribution and can introduce noise if not properly calibrated:
- Overgeneralization (Over-smoothing): If is too large, SMOTE may interpolate between samples that are far apart, potentially spanning across majority class regions and creating "spy samples" (noise).
- Sensitivity to Outliers: If an anchor point is a minority outlier (noise), SMOTE will generate synthetic points between that outlier and its neighbors, creating a bridge of noise through the majority class.
- Categorical Constraints: In its vanilla form, SMOTE is unsuitable for discrete features. For datasets containing categorical variables, variants such as SMOTE-NC must be employed to handle non-continuous manifolds.
Advanced Variants
To mitigate these risks, architectures like Borderline-SMOTE focus exclusively on samples located at the edge of the decision boundary, where the risk of misclassification is highest, thereby optimizing the sampling efficiency.
5. Architectural Conclusion
SMOTE represents a formal shift from data replication to data synthesis. By leveraging the geometric properties of the feature space, it provides a rigorous framework for balancing datasets. When integrated into complex pipelines—such as CNN-LSTM architectures for temporal traffic analysis—SMOTE ensures that the model learns the underlying patterns of rare events without sacrificing performance on the majority class.
[!CAUTION] Implementation Warning: Practitioners must apply SMOTE only to the training partition. Applying oversampling to validation or test sets leads to "data leakage" and artificially inflated performance metrics that do not reflect real-world generalization.