Attention Dynamics: Formalizing Scaled Dot-Product Mechanisms in Transformer Architectures
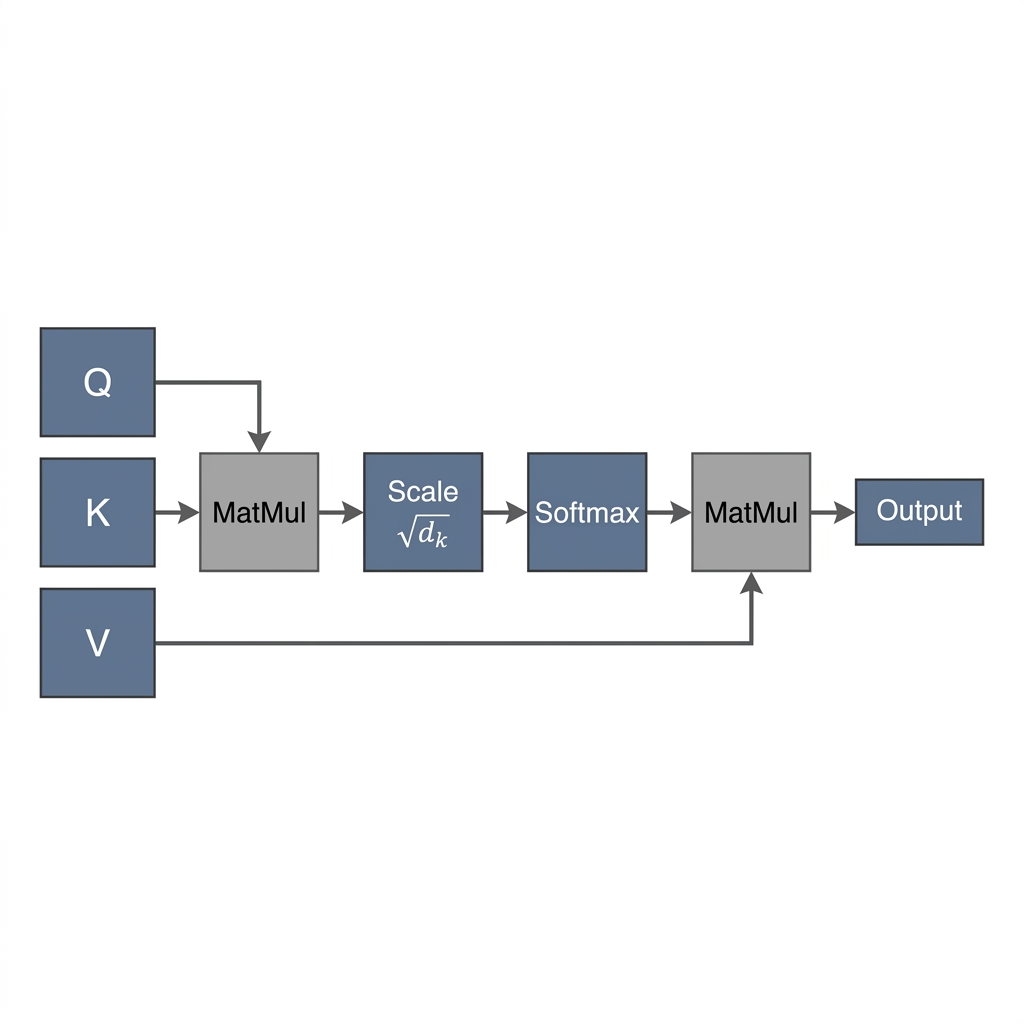
The paradigm shift from sequential Recurrent Neural Networks (RNNs) to the Transformer architecture is predicated on the Self-Attention mechanism. Unlike its predecessors, which constrained information flow to a linear temporal axis, Self-Attention enables an associative memory paradigm where every token in a sequence interacts globally and simultaneously. This paper formalizes the Scaled Dot-Product Attention mechanism and its underlying mathematical duality.
1. The Associative Memory Paradigm: Q, K, and V
In the Transformer architecture, each input token is projected into three distinct latent spaces, forming a relational database heuristic:
- Query (): The search vector representing the current token's requirements ("What information do I need from the context?").
- Key (): The indexing vector representing the token's identity for other queries ("What information do I offer to the context?").
- Value (): The semantic vector containing the actual payload to be extracted once a match is identified.
Every token simultaneously assumes the role of a Query, a Key, and a Value, facilitating complex, multi-dimensional relational mapping across the entire sequence length .
2. The Calculus of Attention: Scaling and Softmax
The interaction between tokens is governed by the Scaled Dot-Product Attention formula:
Procedural Mechanics:
- Similarity Measurement: The dot product measures the alignment between queries and keys. A higher magnitude indicates a stronger relational affinity.
- Scaled Normalization: Dividing by (the square root of the key dimension) ensures that the dot products do not grow excessively large, which would cause the gradients of the Softmax function to vanish.
- Probability Distribution: The Softmax function transforms raw scores into a normalized probability distribution across all keys.
- Context Aggregation: The final output is a weighted sum of the Values, where the weights are determined by the Softmax distribution.
3. Practical Simulation: Associative Relational Space
Try interacting with the simulated Attention Space below to visualize how the model dynamically re-prioritizes context based on the active Query token.
{"component":"LlmGeneratedComponent","props":{"height":"600px","prompt":"Objective: Build an interactive Self-Attention Score visualizer.\nData State: A sample sentence: 'The animal didn't cross the street because it was too tired'.\nStrategy: Standard Layout.\nInputs: A row of clickable buttons, one for each word in the sentence. These represent the active 'Query' word.\nBehavior: Display the full sentence prominently at the top. Below it, display the core formula: Attention(Q,K,V) = softmax(QK^T / sqrt(d_k))V. When the user clicks a specific word (the Query), calculate and display simulated attention weights between that Query and all other words (the Keys) in the sentence. Display these weights as a bar chart or a heat map directly below the words. \nLogic: Hardcode the simulated attention relationships to be educational. For example, if the user clicks 'it', the highest weight (e.g., 75%) should land on 'animal', a medium weight on 'tired', and very low weights elsewhere. If they click 'tired', it should attend strongly to 'animal' and 'it'. Visually highlight the relationship between the selected Query word and the resulting Key weights.","id":"im_a5747dd413deb90c"}}
4. Mathematical Derivation: A Step-by-Step Proof
To demonstrate the robustness of the mechanism, we analyze the attention output for a sample sequence: "Cat sits".
Step 1: Input Projections
Given input and learned weight matrices :
Step 2: Similarity and Scaling
The raw similarity matrix results in:
Applying the scaling factor :
Step 3: Distribution and Context-Aware Output
Applying the row-wise Softmax () yields the attention weights:
The final contextualized representation is the product :
5. Architectural Conclusion
Through the Self-Attention mechanism, tokens are transformed from static embeddings into dynamic high-dimensional vectors that encapsulate their entire neighborhood. The "Cat" vector at the output layer is no longer a general representation of the entity but specifically a representation of a "Cat that sits". This density of context is what allows Transformers to achieve state-of-the-art performance in natural language understanding.
{"component":"LlmGeneratedComponent","props":{"height":"700px","prompt":"Objective: Build an interactive matrix math visualizer for the Transformer Self-Attention calculation.\nData State: Input X = [[1,0,1], [0,1,1]]. Weights W_Q = [[1,0],[0,1],[0,0]], W_K = [[1,1],[0,1],[1,0]], W_V = [[0,1],[1,0],[1,1]]. Initial calculated matrices Q = [[1,0],[0,1]], K = [[2,1],[1,1]], V = [[1,2],[2,1]].\nStrategy: Standard Layout.\nInputs: A 'Next Step' button to advance through the 5 phases of the attention formula.\nBehavior: Display the current phase title and the mathematical operation being performed. Phase 1: Show Q, K, and V matrices. Phase 2: Show the matrix multiplication of Q and K-Transpose resulting in the Scores matrix [[2,1],[1,1]]. Phase 3: Show the division by sqrt(2) resulting in Scaled Scores [[1.41, 0.71], [0.71, 0.71]]. Phase 4: Apply Softmax row-wise to show the Weights matrix [[0.67, 0.33], [0.50, 0.50]]. Phase 5: Show the final matrix multiplication of Weights and V, resulting in the Output matrix [[1.33, 1.67], [1.50, 1.50]]. Visually emphasize the matrices changing and progressing through the pipeline.","id":"im_2c233e9a3ce32868"}}