Foundations of Recurrent Architectures: Parameter Sharing and Temporal Dynamics
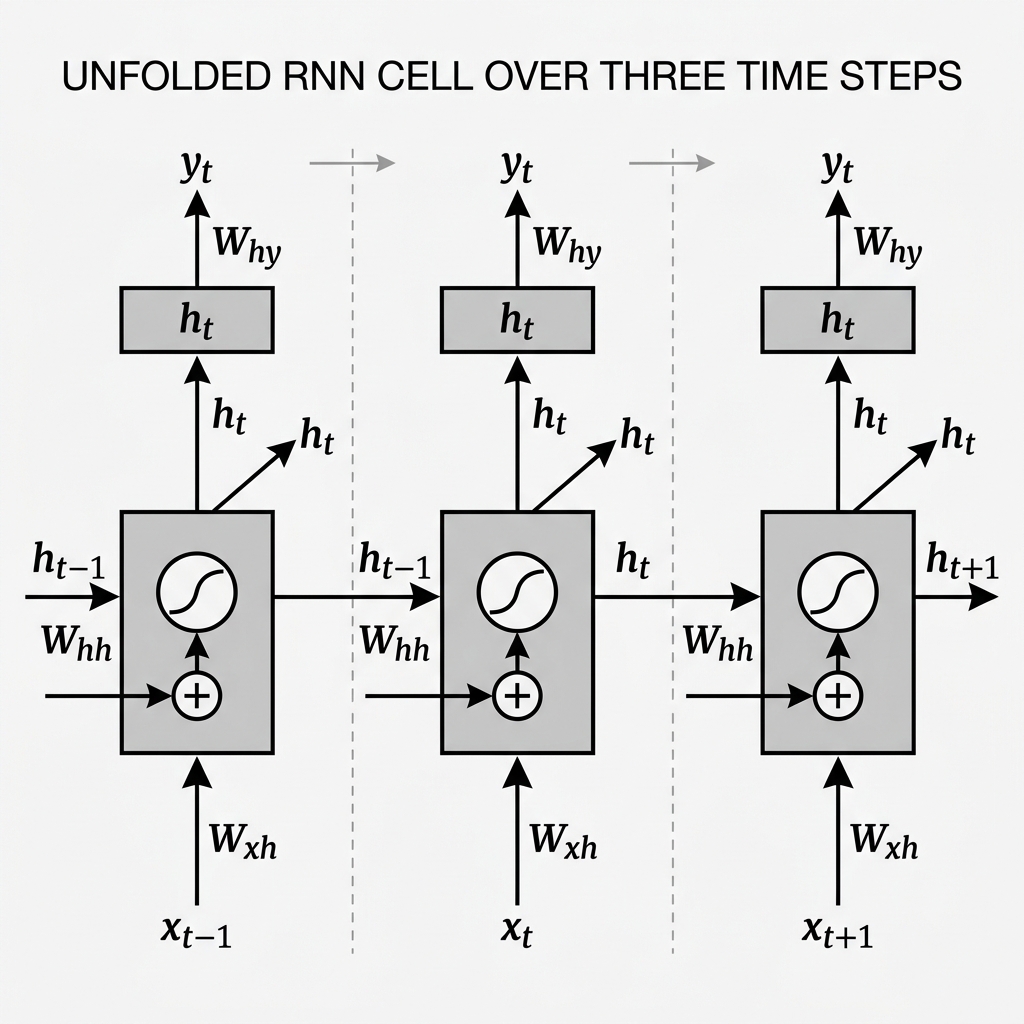
The fundamental abstraction in Recurrent Neural Networks (RNNs) is the mapping of sequential dependencies through Parameter Sharing over Time. Unlike standard Feedforward or Convolutional architectures that operate on fixed-dimensional spatial grids, the RNN architecture is designed to map input sequences of arbitrary length into a continuous latent state space.
This research article formalizes the mathematical transformations within an RNN cell and analyzes the inherent computational constraints of recurrent backpropagation.
1. Architectural Formalism and Notation
Consider a discrete-time sequence , where each . The RNN processes this sequence by maintaining an internal Hidden State , which acts as a summary of the temporal history up to step .
The system is parameterized by the following weight matrices:
- : Input-to-Hidden projection.
- : Recurrent Hidden-to-Hidden transition.
- : Hidden-to-Output projection.
- : Bias vectors for the hidden and output layers, respectively.
2. Temporal State Transitions
At each temporal step , the network executes a dual-stage transformation to update its internal representation and generate an external prediction.
2.1 Hidden State Update (The Recurrent Step)
The transition is governed by a non-linear activation function, typically the hyperbolic tangent (), which squashes the weighted sum of current inputs and previous states:
Deterministic Memory: The new state is a synthesis of the instantaneous signal and the aggregated historical context . The use of is mathematically critical to ensure the stability of the latent state, preventing exponential divergence of values during forward propagation.
2.2 Output Projection
The mapping to the label space is performed by projecting the hidden state through the output matrix, often followed by a normalizing transformation such as Softmax for classification:
3. Mathematical Analysis of Parameter Sharing
A defining characteristic of the RNN is the Temporal Invariance of its parameters. The matrices remain constant across all time-steps .
This provides two significant advantages:
- Computational Efficiency: The number of trainable parameters is independent of the input sequence length, allowing the model to generalize across variable temporal scales.
- Generalization: The model learns a universal "transition rule" that applies regardless of the specific index in the sequence, much like how a Convolutional kernel learns spatial patterns regardless of pixel coordinates.
4. The Vanishing Gradient Constraint
The training of RNNs is performed via Backpropagation Through Time (BPTT). When computing the gradient of the loss with respect to the recurrent weights , the chain rule spans the entire temporal history:
Evaluating a single term in this summation involves a product of Jacobian matrices:
Scientific Bottleneck: Since the derivative of the function is bounded by , and the spectral radius of may be small, long temporal chains cause the gradient to decay exponentially toward zero. This results in the Vanishing Gradient Problem, where the network fails to learn long-range dependencies effectively.
5. Summary of Recurrent Dynamics
| Feature | Deterministic RNN | Analysis |
|---|---|---|
| State Mapping | Markovian dependency on immediate past | |
| Activation | Non-linear stability control | |
| Weight Sharing | Global | Temporal invariance |
| Optimization | BPTT | Vulnerable to vanishing gradients |
| Generalization | Variable-length | Agnostic to sequence length |
[!CAUTION] Key Limitation: While standard RNNs are mathematically elegant, they are practically unsuitable for sequences exceeding 20-50 steps due to the gradient vanishing bottleneck. This necessitated the development of Gated architectures like LSTMs and GRUs.