The Calculus of Compression: Mathematical Foundations of Post-Training Quantization (PTQ)
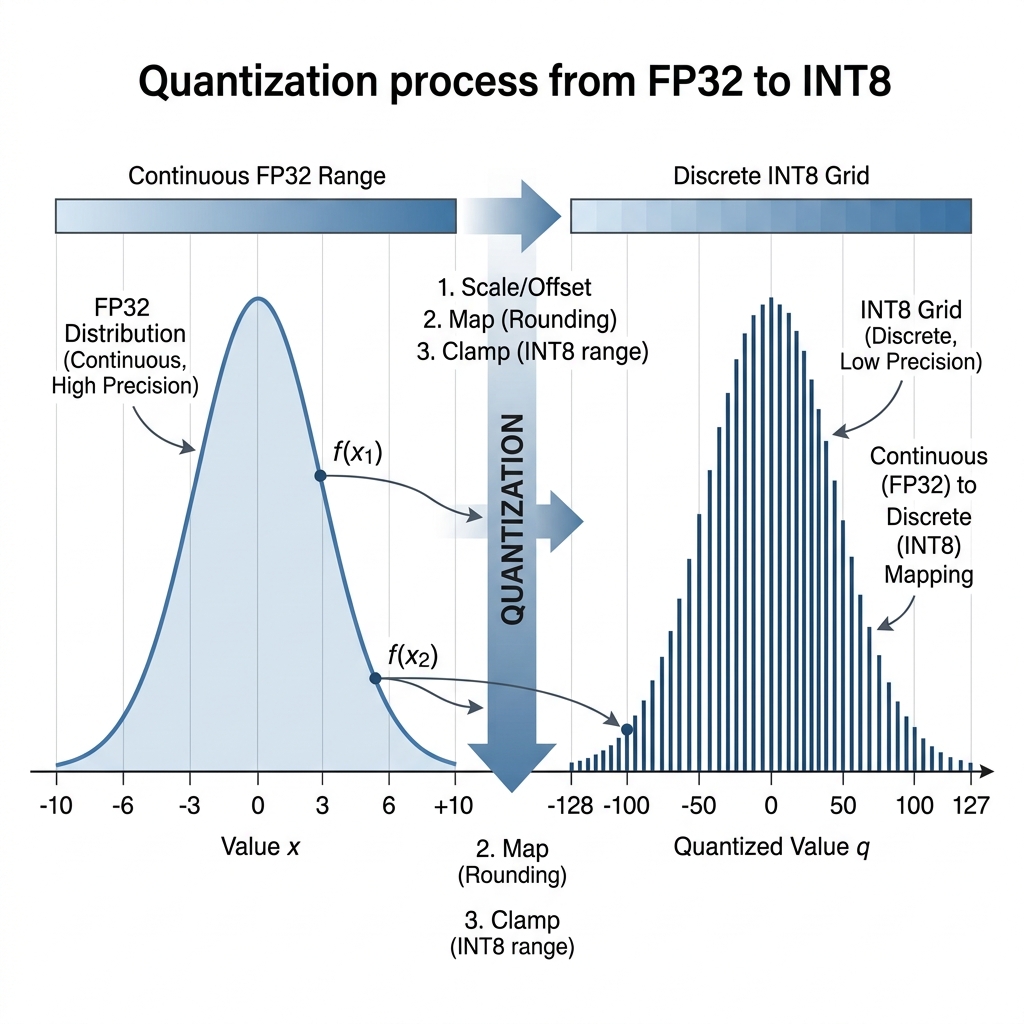
To facilitate the deployment of high-parameter deep learning architectures on edge compute environments, model compression is an algorithmic necessity. Among various techniques—including pruning and knowledge distillation—Quantization remains the most impactful for latency reduction. This paper formalizes the process of Post-Training Quantization (PTQ), focusing on the affine mapping between high-precision floating-point manifolds and discrete integer grids.
1. The Core Objective: Precision Reduction
Quantization is the process of mapping continuous values to a smaller, discrete set of values. In the context of neural networks, this typically involves converting 32-bit floating-point (FP32) weights and activations to 8-bit integers (INT8).
The primary constraint is to minimize the Quantization Error: the divergence between the original high-precision value and its reconstructed dequantized counterpart . This requires an optimal linear mapping that preserves the relative stochastic distributions of the weight tensors.
2. Affine Mapping Formalism: and
Modern quantization frameworks (such as PyTorch’s fbgemm or NVIDIA’s TensorRT) utilize an Affine Mapping scheme. The transformation from a real-valued input to a quantized integer is defined as:
Where:
- (Scale): A strictly positive real number that represents the step size of the quantizer.
- (Zero-point): An integer ensuring that the real value is exactly representable in the quantized domain, preventing bias in zero-padded layers.
- : The operational boundaries of the target bit-depth (e.g., -128 and 127 for signed INT8).
Derivation of Parameters
Given a range of real values , the optimal parameters are derived as follows:
3. Numerical Validation: Kernel Weight Mapping
Consider a subset of weights within a Convolutional Layer defined by the range . To map these values to a signed INT8 range :
- Scale Calculation:
- Zero-point Calculation:
Mapping Execution:
- A value of maps to:
- A value of maps to:
This discrete representation allows the hardware to utilize integer arithmetic units (ALUs) for matrix multiplications, surfacing significant throughput gains.
4. Hardware Acceleration and Throughput
The adoption of INT8 precision triggers specialized hardware execution paths. Floating-point units (FPUs) are bypassed in favor of high-throughput vector instructions:
- x86_64: Utilizes AVX-512 VNNI (Vector Neural Network Instructions) to perform dot products with quadruple the throughput of standard FP32 instructions.
- NVIDIA GPU: Utilizes DP4A (Dot Product 4-way Accumulate) or Tensor Cores, which are optimized specifically for low-precision fused multiply-add operations.
- ARM/Mobile: Utilizes NEON SIMD registers, significantly reducing power consumption—a critical metric for edge ecosystems like PomaiDB.
5. Architectural Trade-offs: The Accuracy Gap
The primary trade-off in quantization is the introduction of Rounding Noise. While linear layers are generally robust, a naive PTQ application can lead to a degradation in top-1 accuracy. To mitigate this, practitioners employ Quantization-Aware Training (QAT), where the model is fine-tuned with simulated quantization noise, allowing the backpropagation algorithm to optimize weights for the discrete grid.
[!IMPORTANT] Implementation Strategy: For edge-focused deployments, PTQ should be the first-pass optimization. QAT is reserved for scenarios where structural sensitivity (e.g., in depthwise separable convolutions) leads to unacceptable accuracy regressions.