Computational Efficiency in Edge AI: Optimization via Pythonic Lazy Evaluation
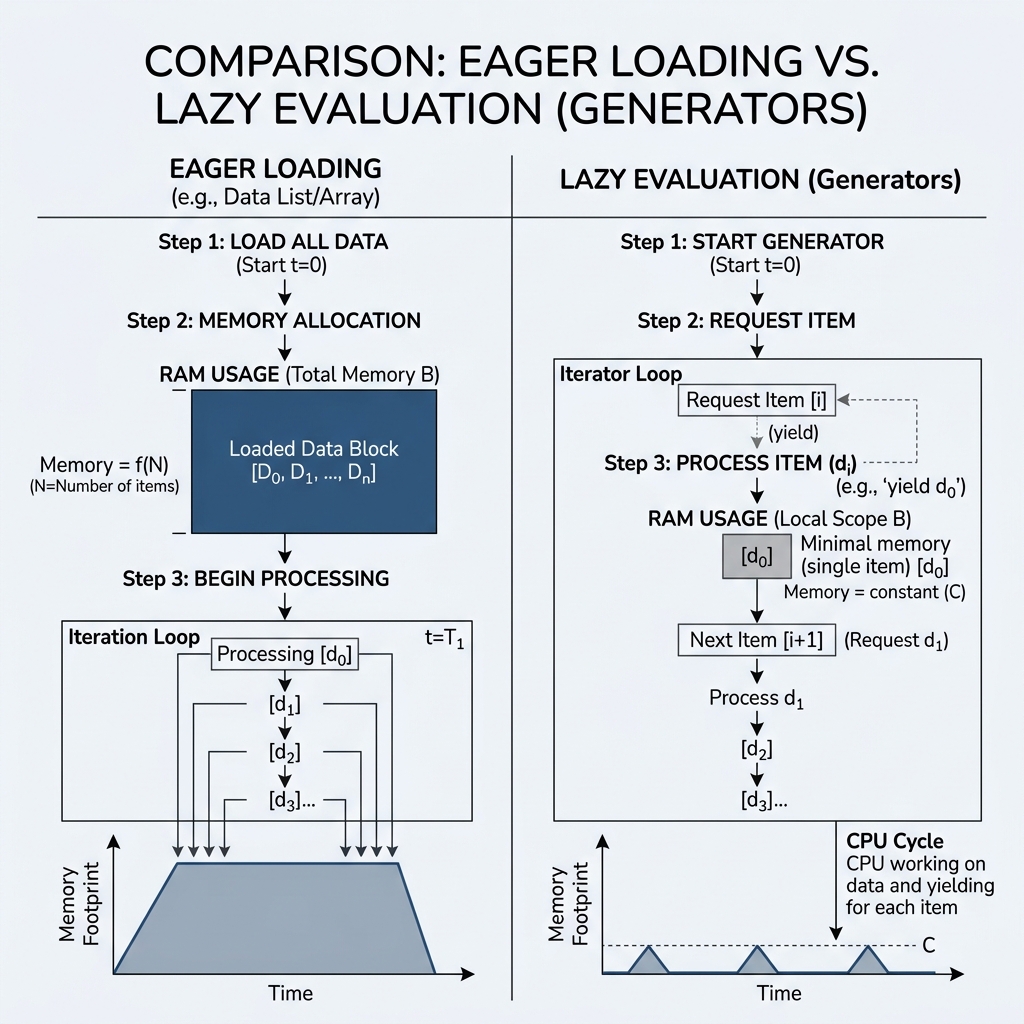
In the deployment of Deep Learning models on Edge devices (e.g., NVIDIA Jetson, Raspberry Pi), memory bandwidth and allocation efficiency are primary bottlenecks. While standard data ingestion patterns often rely on Eager Loading—where datasets are materialized in RAM entirely before processing—this approach scales poorly.
This study examines the use of Lazy Evaluation through Python’s yield keyword to facilitate memory-efficient data streaming in constrained environments.
1. Mathematical and Systemic Context
The core challenge of large-scale data ingestion is the trade-off between Throughput and Memory Footprint.
- Eager Loading: An memory operation where is the dataset size.
- Lazy Evaluation (Generators): An memory operation relative to the batch size, regardless of the total dataset magnitude.
By utilizing the yield statement, a function is transformed into a Generator, which implements the Iterator Protocol. Instead of returning a concrete data structure, it returns a stateful object that produces values on-demand.
2. Mechanics of the yield Primitive
The yield keyword operates as a non-preemptive context-switching mechanism. When the Python interpreter encounters yield, the current function state (including local variables, instruction pointer, and exception stack) is suspended and serialized.
Theoretical Comparison: return vs. yield
| Metric | Return-based Materialization | Yield-based Streaming |
|---|---|---|
| State Retention | Final State Only (Stack cleared) | Persistence of local frame |
| Memory Complexity | per yield | |
| Execution Pattern | Synchronous/Blocking | Iterative/Lazy |
| Concurrency | Limited to thread/process | Coroutine-friendly |
3. Implementation Analysis
Consider a scenario where an Edge device must process a high-frequency sensor stream or a massive telemetry log.
def stream_sensor_data(file_path):
with open(file_path, 'r') as f:
for line in f:
# Mathematical transformation or normalization
processed_signal = normalize(line)
yield processed_signal # Suspend and emit
In this implementation, even if the file_path points to a 100GB dataset, the RAM utilization will remain constant (roughly the size of a single buffer line). This is critical for Continuous Learning systems where data is processed as a stream rather than a static batch.
4. Performance Implications for Edge AI
- Cache Locality: By processing data in smaller, immediate chunks, generators can improve CPU cache hits compared to iterating over massive arrays that exceed the L3 cache.
- Latency Masking: I/O operations can be interleaved with computation. While the CPU processes chunk , the I/O subsystem can fetch chunk in the background.
- Stability: Preventing Out-of-Memory (OOM) errors is paramount in autonomous systems. Generators provide a deterministic upper bound on memory usage.
[!IMPORTANT] Scientific Conclusion: For production-grade AI on the edge, manual memory management via generators is not an "optimization" but a requirement. Materializing large lists is the most common cause of non-deterministic system failure in embedded Python environments.