Automata as Memory: Decoding LSTM State Persistence in Terminal Sequences
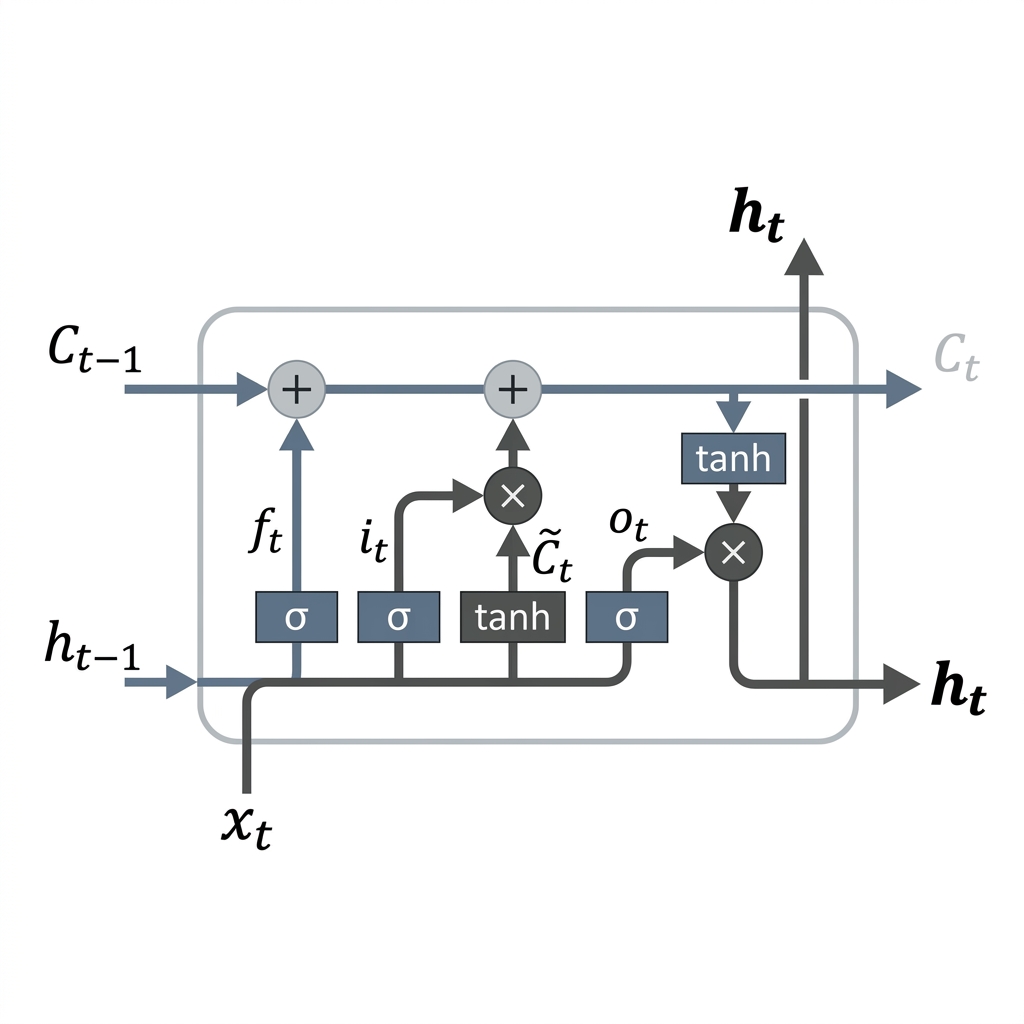
In the architectural study of Recurrent Neural Networks (RNNs), specifically the Long Short-Term Memory (LSTM) variant, a critical point of confusion often arises regarding the terminal behavior of the cell. At the final time-step of a sequence, the LSTM unit produces two distinct state vectors: the Cell State () and the Hidden State ().
This paper formalizes the functional divergence of these states and clarifying their utilization in downstream computational layers.
1. Functional Duality: vs.
The LSTM architecture is defined by its ability to modulate information flow through a system of gating mechanisms. This leads to a fundamental duality in its internal representation:
- Cell State (): Representing the "Long-Term Memory" or the internal conveyor of information. It acts as a high-capacity buffer that persists across time-steps with minimal linear interactions, mitigating the vanishing gradient problem.
- Hidden State (): Representing the "Short-Term Memory" or the active output of the cell. It is a filtered, non-linear projection of the current Cell State, designed to be consumed by the next layer or the next time-step.
At the terminal step , both vectors are computed, but their subsequent roles differ based on the network topology.
2. Mathematical Formalism of the Terminal Transition
The computation at the terminal step follows the standard LSTM transition equations. There is no structural deviation at . The state updates are governed by the Forget (), Input (), and Output () gates:
The final states are then derived as:
Where denotes the Hadamard product. Once the sequence is exhausted, the recursion terminates, and the states are passed to the terminal interface.
3. Downstream Topology and State Utilization
The decision to utilize , , or both is strictly task-dependent. We categorize these into two primary architectural patterns:
Pattern A: Many-to-One (Sequence Classification)
In tasks such as sentiment analysis or document categorization, the objective is to map a sequence to a single categorical distribution.
- Mechanism: The network consumes the entire sequence. At , only the Hidden State () is extracted.
- Transformation: .
- State Persistence: The Cell State is discarded as its role in maintaining long-term gradients is complete.
Pattern B: Many-to-Many (Sequence-to-Sequence / Encoder-Decoder)
In neural machine translation or generative tasks, the LSTM acts as an Encoder that must "hand over" the compressed context to a Decoder.
- Mechanism: To preserve the maximum information density, the Encoder transmits both and .
- Transformation: The Decoder is initialized such that and .
- State Persistence: Here, is essential as it carries the "core" context that has not been filtered by the final output gate , providing the Decoder with a richer initialization.
4. Architectural Conclusions
The distinction between the Hidden State and Cell State at the terminal step is not one of mathematical difference, but of functional utility. While serves as the summarized representation of the sequence for immediate inference, remains the primary vessel for long-distance context preservation. In multi-layered (stacked) LSTM architectures, both states are propagated vertically to the subsequent layer, ensuring the "memory" remains intact across the model's depth.
[!NOTE] Research Insight: While is a filtered version of , using for prediction is generally preferred as it incorporates the non-linear gating logic necessary to suppress noise and focus on task-relevant features.