Inverse Diffusion and Latent Manifolds: Formalizing Generative Mechanics in AI Synthesis
In the current paradigm of Artificial Intelligence, Generative AI represents a shift from discriminative classification to a constructive synthesis of high-dimensional data. Rather than simple pattern recognition or heuristic templates, modern generative systems operate by mapping high-entropy noise distributions to low-entropy manifolds of structured information.
This paper formalizes the primary mechanisms of data synthesis, specifically the Diffusion process and Latent Space operations, providing a rigorous mathematical framework for understanding how machines "create" from nothingness.
1. Stochastic Prediction: The Foundation of Generative Systems
At their core, all generative models are probabilistic estimation engines. Whether generating text (Large Language Models) or visual information (Diffusion models), the objective is to model the underlying probability distribution of the training data.
- Textual Synthesis (Transformers): These models function as autoregressive probability calculators. Given a sequence of tokens , the model predicts the conditional probability . The process is discrete and iterative, where each token is sampled based on a non-linear projection of the preceding context window.
- Visual Synthesis (Diffusion/GANs): Unlike the discrete steps of text, visual synthesis involves the manipulation of continuous pixel manifolds. The objective is to transform a standard Gaussian noise vector into a structured image that satisfies the learned distribution of the visual world.
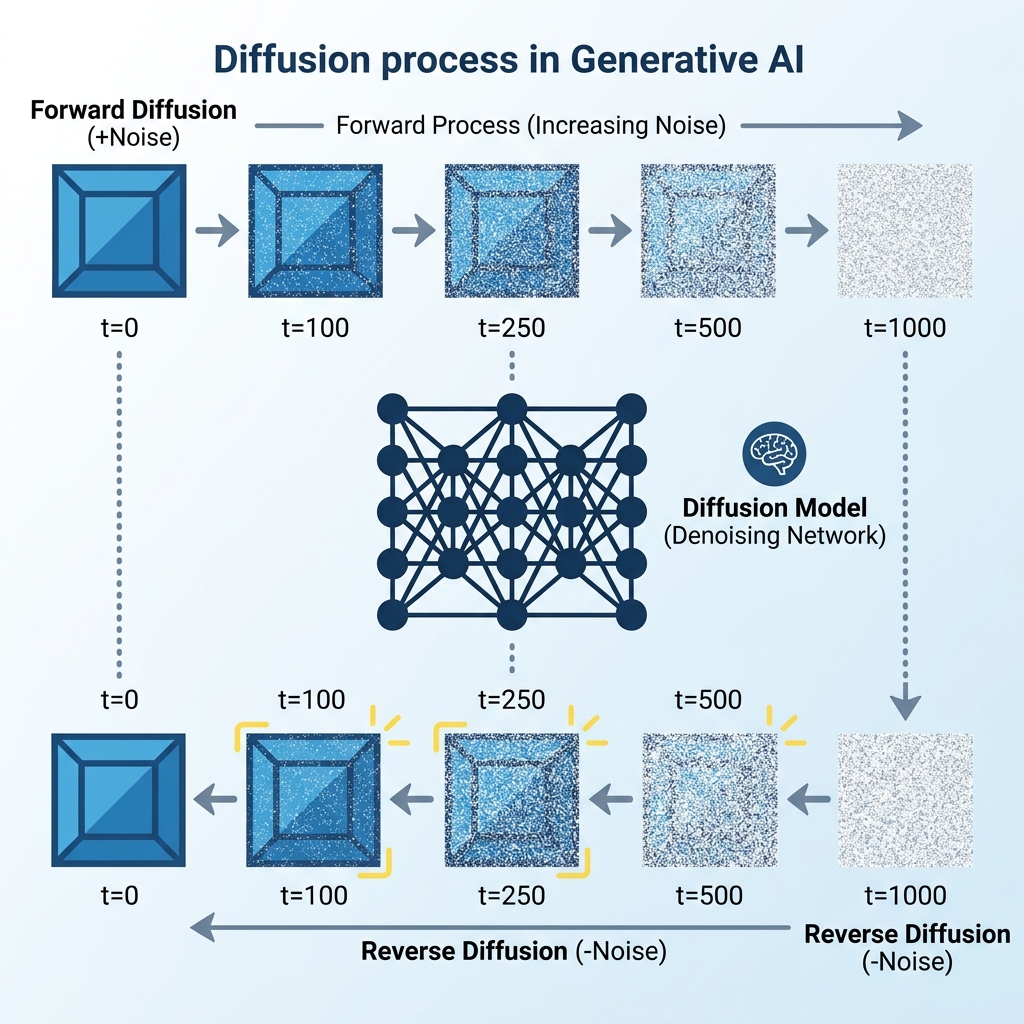
2. Diffusion Dynamics: Sculpting via Denoising
The Diffusion Model (e.g., Stable Diffusion, DALL-E) has become the state-of-the-art mechanism for image generation. Its core logic is counter-intuitive: to teach a model to build an image, one must first teach it how to systematically destroy it.
Forward Diffusion (The Markovian Decay)
During the training phase, an image is progressively corrupted by adding infinitesimal amounts of Gaussian noise over steps (typically ). The transition is defined as:
As , the original structure vanishes, and the image converges to pure isotropic noise.
Reverse Diffusion (The Generative Inverse)
Synthesis occurs in the reverse direction. Starting from a random noise tensor , a neural network predicts the noise component present at each step and subtracts it. The goal is to estimate the reverse transition:
The model does not "remember" the image; it learns the score function—the gradient of the log-density that "pushes" the noise toward the high-density regions of the data manifold.
3. Numerical Derivation: A Discrete Signal Case Study
To concretize the mechanism, we analyze a simplified case of a grayscale image represented as a matrix .
Input Configuration
- Target Matrix (): A high-contrast "checkered" pattern.
- Initial Noise (): A random starting state for synthesis.
The Denoising Step
Given the target context (e.g., prompt = "high-contrast pattern"), the model predicts the noise to be removed.
Iteration 1: The model calculates a gradient to "nudge" the pixels toward the learned pattern:
Updating the state: (where is a scaling factor). For simplicity:
Iteration 2: The updated state continues to move toward the manifold:
By the terminal step, the random noise has been "sculpted" into a matrix that is mathematically indistinguishable from the target .
4. Adversarial Dynamics: Generative Adversarial Networks (GANs)
Prior to the dominance of Diffusion, GANs utilized a competitive game-theoretic framework. A GAN consists of two networks in a zero-sum game:
- Generator (): Maps a latent vector to the data space, .
- Discriminator (): Maps a sample to a probability , outputting 1 for real and 0 for fake.
The objective function is defined as:
The system reaches Nash Equilibrium when the Generator produces samples so realistic that for all , indicating total ambiguity.
5. Semantic Compression: Latent Manifold Learning
A critical innovation in modern generative systems is the move from Pixel Space to Latent Space. Operating directly on high-resolution pixels () is computationally prohibitive.
Generative models utilize a Variational Autoencoder (VAE) to compress the image into a low-dimensional latent representation .
- Chairs, faces, and landscapes become coordinates in this multi-dimensional vector space.
- Arithmetic operations on these vectors correspond to semantic changes (e.g., ).
By performing the Diffusion process in this compressed latent space (Latent Diffusion), models achieve high-order creativity with manageable compute requirements.
6. Architectural Conclusion
Generative AI is not an act of "copying" but of manifold navigation. By leveraging the stochastic calculus of Diffusion and the competitive dynamics of GANs, these architectures learn to traverse the latent manifolds of human knowledge. The transition from noise to signal is a controlled descent into structured probability, enabling machines to synthesize information that is both novel and statistically consistent with our reality.
[!NOTE] Research Insight: The effectiveness of these models relies on the Central Limit Theorem—as noise is added, any distribution eventually becomes Gaussian. By learning to reverse this universal decay, AI captures the fundamental signatures of data structure across all modalities.