Distributed Data Parallel (DDP) Architecture: Mathematical Foundations of Ring All-Reduce
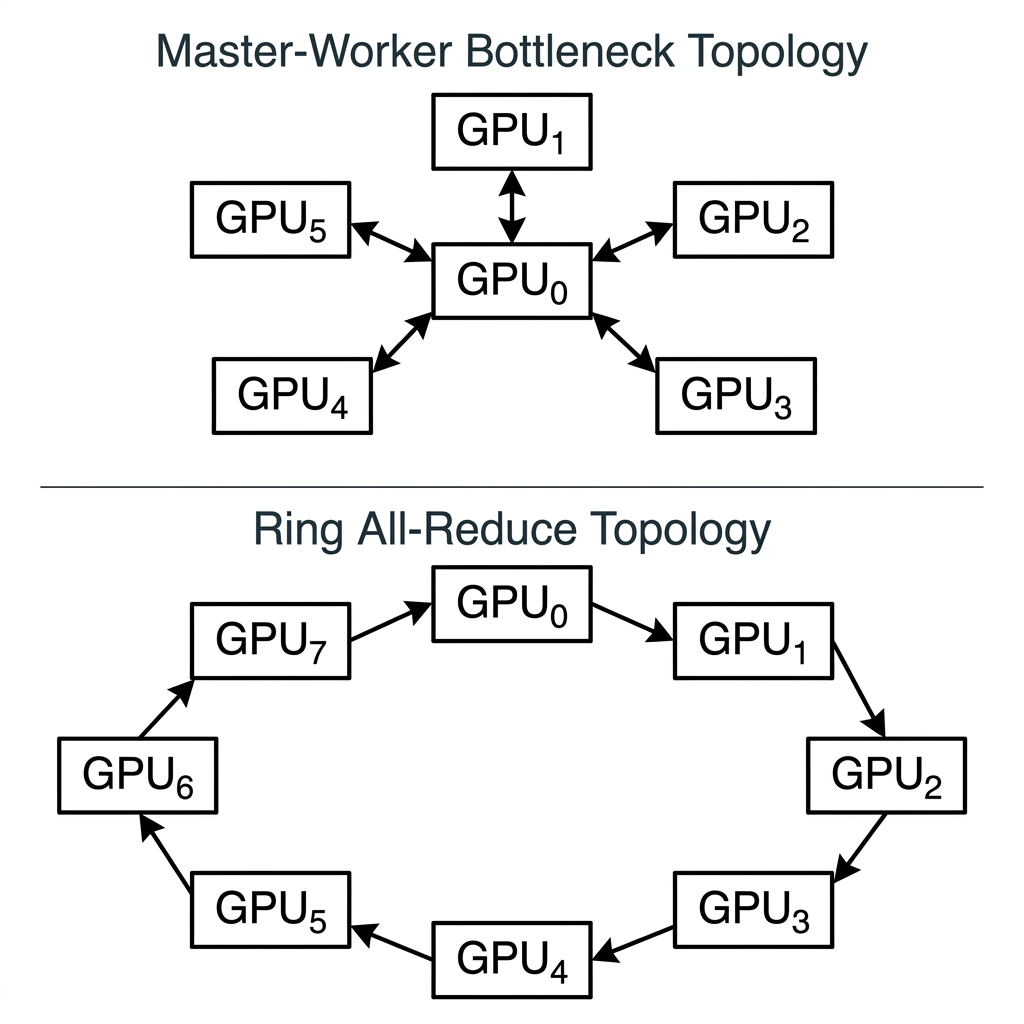
Scaling deep neural network architectures across multiple GPU accelerators requires sophisticated communication topologies. While early implementations relied on threaded Master-Worker paradigms, modern systems employ Distributed Data Parallel (DDP) protocols. This paper formalizes the architectural shift from legacy DataParallel (DP) to DDP, focusing on the mechanics of the Ring All-Reduce algorithm.
1. The Bottleneck: Why Legacy DataParallel (DP) Fails
To appreciate the architectural elegance of DDP, we must analyze the structural flaw in its predecessor, DataParallel (DP). DP operates using Multi-threading under a single Python process.
Due to the Global Interpreter Lock (GIL), only one thread can execute Python bytecode at a given moment. In the DP architecture, a designated "Master GPU" (typically GPU ) assumes a disproportionate communication burden:
- Sharding the input minibatch.
- Broadcasting model weights to all adjacent GPUs.
- Gathering all forward-pass outputs.
- Computing the global loss tensor.
- Gathering all gradients from the backward pass.
- Applying the optimizer step locally and re-broadcasting.
Complexity Analysis: If represents the model parameter footprint, the Master GPU must broadcast copies of and gather copies of gradients per iteration. This strictly limits scalability, creating an asymptotic communication bottleneck bounded by the PCIe bandwidth and CPU/GPU contention of the Master node.
2. The DDP Solution: Multi-Processing Topologies
DDP resolves the GIL limitation via Multi-processing. Each GPU is assigned a dedicated OS process. These processes do not share a memory space; they function as isolated, autonomous workers. By eliminating the "Master GPU" hub, DDP achieves near-linear scaling efficiency.
The crux of DDP's efficiency lies in its gradient synchronization algorithm: Ring All-Reduce.
The Ring All-Reduce Algorithm
Instead of a centralized hub, GPUs are logically arranged in a circular ring topology. Gradient synchronization occurs in two mathematically defined phases:
Phase A: Scatter-Reduce
The gradient tensor computed by GPU is partitioned into contiguous chunks.
- GPU transmits chunk to GPU .
- The receiving GPU adds its own chunk to the incoming data and transmits the summation to the next node.
- After iterations, each GPU holds the complete, globally reduced sum for exactly one subset of the gradient tensor.
Phase B: All-Gather
The distributed, fully reduced chunks must now be synchronized globally.
- GPU transmits its fully computed chunk to GPU .
- This data is passed around the ring unaltered.
- After iterations, every GPU in the cluster possesses the identical, globally synchronized gradient tensor.
Mathematical Formalism: Let denote the local gradient tensor computed by worker . The synchronized gradient applied globally to all model replicas is:
3. Communication/Computation Overlap
The DDP wrapper intercepted the loss.backward() hook through a system of "buckets." This allows for the Overlap of Communication and Computation:
- While the GPU computes gradients for layers closer to the input (proximal layers), the NCCL backend immediately begins broadcasting/reducing gradients of layers already computed (distal layers).
- This asynchrony masks the network latency behind the time required for backpropagation on the GPU.
4. Architectural Conclusions
The transition to Distributed Data Parallel is not merely an optimization; it is a requirement for training foundational models. Legacy DataParallel should be deprecated in favor of DDP, even on single-node workstations, due to its elimination of the GIL bottleneck and optimal bandwidth utilization .
[!CAUTION] Implementation Warning: When utilizing DDP, researchers must ensure the use of a
DistributedSamplerto guarantee that identical data indices are not processed by multiple workers, which would effectively diminish the batch size benefits.