Autoregressive Masking: Formalizing the Causal Mask in Transformer Decoder Architectures
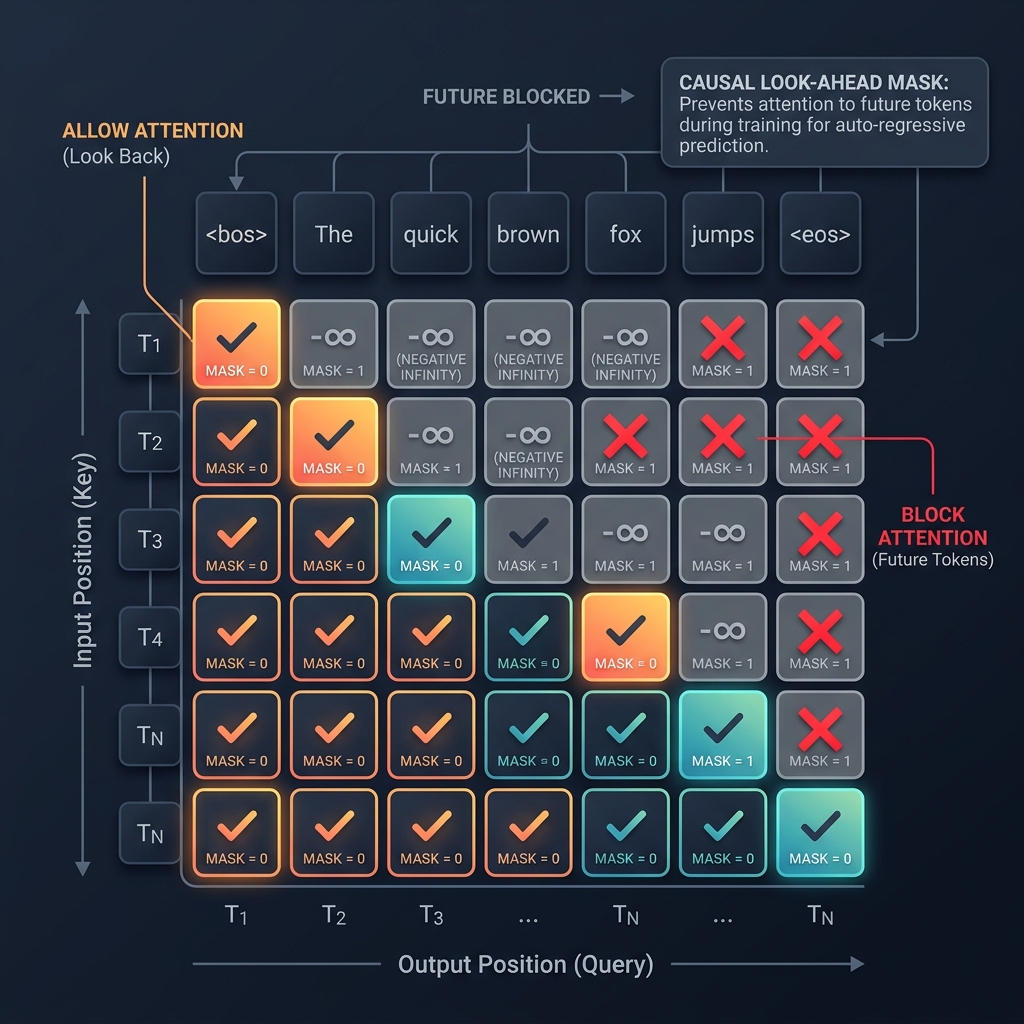
In Transformer architectures, the Self-Attention mechanism grants every token in a sequence unrestricted access to all other tokens simultaneously. While this property is desirable for bidirectional comprehension tasks, it introduces a fundamental constraint violation in autoregressive generation: a model trained to predict the next token must not have access to the tokens it is tasked with predicting. The Causal Mask (also referred to as a future mask or look-ahead mask) is the structural mechanism that enforces this sequential dependency, transforming a globally-attending Transformer into a strictly autoregressive generator.
1. The Information Leakage Problem
Unlike Recurrent Neural Networks (RNNs), which process tokens sequentially along a temporal axis, Transformers process the entire input sequence in parallel. The Self-Attention mechanism allows every token to compute its contextual representation by attending to all other tokens in the sequence simultaneously.
This parallelism, while computationally efficient, creates a critical training vulnerability. Consider a model trained to predict the next word in "The cat sat on the mat". During the forward pass, the token "sat" can attend to "on" — a future token — and trivially read off the answer it is supposed to predict. The model learns to exploit this leakage rather than develop genuine predictive capability.
When deployed autoregressively at inference time, no future tokens exist. A model trained with this leakage would fail to generalize, as the information source it learned to rely upon is unavailable.
2. The Causal Mask: Structural Definition
The Causal Mask is applied to the raw attention score matrix immediately prior to the Softmax operation. It enforces the constraint that token at position may only attend to tokens at positions .
Formally, the mask is defined as an upper-triangular matrix:
The masked score matrix becomes , which is then passed into Softmax:
For a three-token sequence "The cat sat", the mask takes the following form:
| "The" (1) | "cat" (2) | "sat" (3) | |
|---|---|---|---|
| "The" (1) | |||
| "cat" (2) | |||
| "sat" (3) |
3. Mathematical Basis: Softmax Annihilation via
The choice of as the blocking value is not arbitrary. It exploits a fundamental property of the exponential function at the core of the Softmax operation.
Recall the Softmax definition for a score vector :
When :
This causes the corresponding Softmax output to be exactly zero, not merely negligible. The masked tokens contribute nothing to the weighted sum over Values , guaranteeing a hard information boundary rather than a soft penalty.
The resulting attention weight matrix for "The cat sat" demonstrates this property:
| Attention Weights | "The" (1) | "cat" (2) | "sat" (3) |
|---|---|---|---|
| "The" (1) | 100% | 0% | 0% |
| "cat" (2) | 40% | 60% | 0% |
| "sat" (3) | 20% | 30% | 50% |
Token "The" attends exclusively to itself. Token "cat" distributes its attention over "The" and "cat". Token "sat" has access to all prior tokens but is entirely blind to any future context.
4. Step-by-Step Numerical Derivation
To demonstrate the mechanism concretely, we trace the full attention computation for the three-token sequence "The cat sat" (, ).
Step 1: Input Projections
Given token embeddings and learned projection matrices, we obtain:
Step 2: Raw Score Matrix
The unscaled dot-product similarity matrix :
Applying the scaling factor :
Step 3: Applying the Causal Mask
The mask matrix for blocks all upper-triangular entries:
The masked score matrix :
Step 4: Row-Wise Softmax
Softmax is applied independently to each row of . Since , the future positions vanish exactly.
Row 1 ("The"):
Row 2 ("cat"):
Row 3 ("sat"):
The complete attention weight matrix :
Step 5: Context-Aware Output
The final output produces causally-constrained contextual representations:
The output vector for "sat" () encodes context drawn exclusively from "The" and "cat" — the causally valid prior tokens — with zero contribution from any future position.
5. Architectural Scope: Decoder-Only vs. Encoder-Only Models
The causal mask is the defining structural feature that differentiates Decoder-only from Encoder-only architectures.
| Attribute | Decoder-Only (e.g., GPT) | Encoder-Only (e.g., BERT) |
|---|---|---|
| Masking Strategy | Causal (Lower-Triangular) | None (Bidirectional) |
| Attention Direction | Left-to-right (past only) | Unrestricted (past and future) |
| Primary Task | Autoregressive text generation | Contextual representation / Classification |
| Training Objective | Next-token prediction | Masked Language Modeling (MLM) |
In GPT-family models, the causal mask is applied at every Self-Attention layer across the entire decoder stack. This enforces strict autoregressive generation: each token's representation is conditioned exclusively on prior context, enabling the model to sample the next token from a probability distribution during inference.
BERT, by contrast, omits the causal mask entirely. Its bidirectional attention allows each token to incorporate context from the full sequence in both directions, producing richer semantic embeddings suited for understanding and classification tasks rather than sequential generation.
6. Architectural Conclusion
The Causal Mask resolves a fundamental conflict between the Transformer's parallel processing paradigm and the sequential dependency requirement of autoregressive generation. By injecting into the upper triangle of the attention score matrix, it exploits the Softmax's exponential structure to produce a hard, exact zero for all future token interactions. This mechanism enables Decoder-only models to be trained on the full sequence in parallel — retaining the computational advantages of the Transformer — while guaranteeing that the learned representations remain causally consistent with the autoregressive inference procedure.
[!NOTE] Research Insight: In practice, is approximated by a large negative constant (e.g., or ) to avoid numerical overflow in floating-point implementations, while still producing a Softmax output that is numerically indistinguishable from zero.