Statistical Tokenization: Formalizing the Byte Pair Encoding (BPE) Algorithm for Subword Decomposition
In the architectural pipeline of modern Large Language Models (LLMs) such as GPT-4, LLaMA, and Gemini, the transformation of raw text into a discrete numerical manifold begins with Tokenization. Among various methodologies, Byte Pair Encoding (BPE) has emerged as the definitive standard for subword segmentation. This paper formalizes the BPE algorithm, analyzing its ability to mitigate the Out-of-Vocabulary (OOV) problem while maintaining high information density.
1. The Tokenization Dilemma: Granularity vs. Vocabulary Size
Before the advent of subword algorithms, text was tokenized at two extreme levels of granularity, both exhibiting significant limitations:
- Word-level Tokenization: Segmenting by whitespace creates a sparse, high-dimensional dictionary (often exceeding unique tokens). This leads to a massive parameter footprint and frequent Out-of-Vocabulary (OOV) failures when the model encounters novel or rare morphological variants.
- Character-level Tokenization: Segmenting by individual bytes/characters results in a minimal dictionary (e.g., 256 unique tokens) but creates excessively long sequences. This overwhelms the model's Context Window and dilutes semantic representations, as individual characters carry negligible semantic entropy.
BPE serves as the optimal middle ground, leveraging data-driven statistical probability to construct a subword vocabulary that balances dictionary size with sequence length.
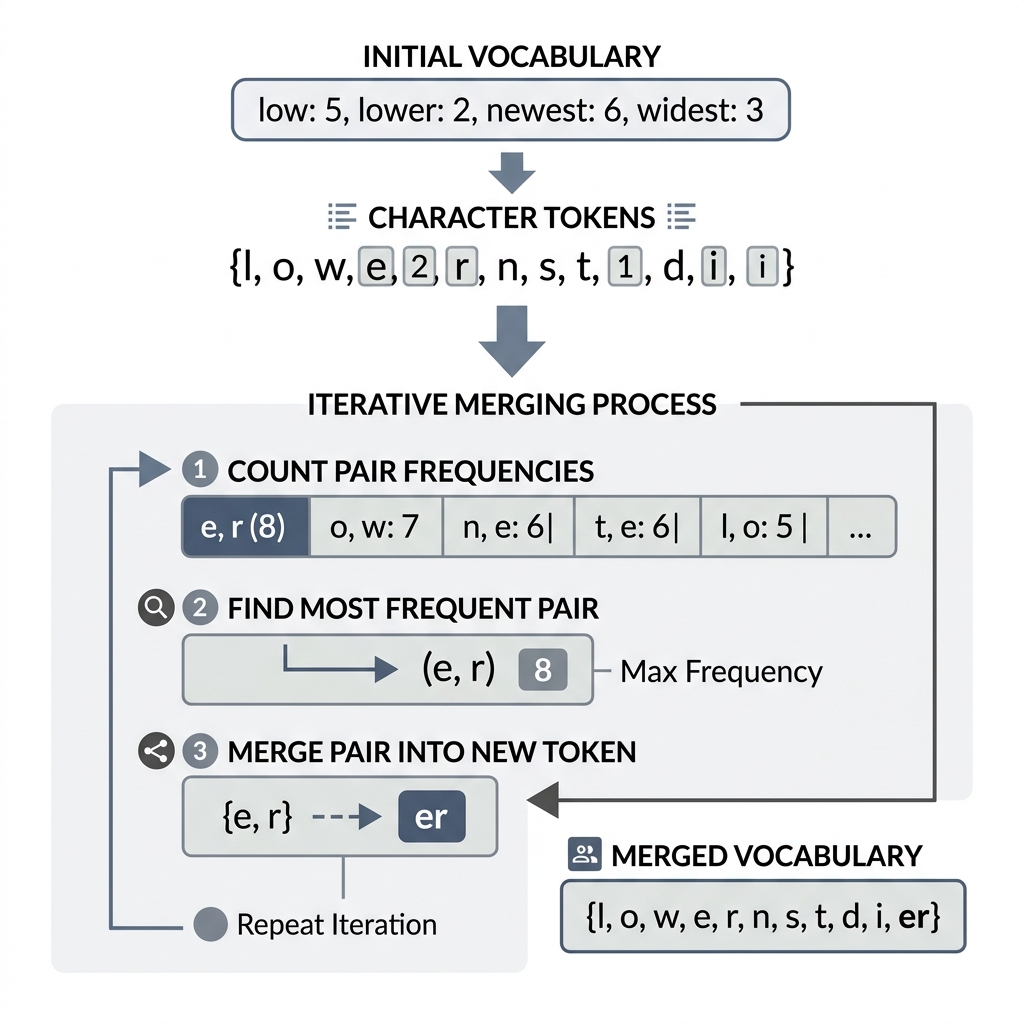
2. Algorithmic Mechanics: Iterative Recursive Merging
The BPE algorithm constructs its vocabulary through an iterative, bottom-up process. It begins at the highest granularity (characters) and progressively builds semantic density through frequency-based merging.
The BPE Calibration Loop:
- Initialization: The training corpus is decomposed into individual byte sequences, with a designated terminal token (e.g.,
_) appended to demarcate word boundaries. - Pair Frequency Analysis: The algorithm scans the corpus to identify all adjacent token pairs and calculates their global occurrence frequency.
- Recursive Merging: The pair with the highest frequency is merged into a singular, unified token. This new token is added to the model's vocabulary.
- Corpus Update: All occurrences of the selected pair are replaced with the new token throughout the corpus.
- Termination: The process repeats until a pre-defined vocabulary capacity is achieved.
3. Practical Simulation of Recursive Merging
Below is an interactive simulation of the BPE algorithm's calibration phase. Observe how the algorithm remains agnostic to human grammar, instead optimizing for statistical co-occurrence.
{"component":"LlmGeneratedComponent","props":{"height":"700px","prompt":"Objective: Create an interactive step-by-step Byte Pair Encoding (BPE) algorithm simulator.\nData State: A sample dataset representing a corpus dictionary with frequencies: { 'l o w _': 5, 'l o w e s t _': 2, 'n e w e r _': 6, 'w i d e r _': 3 }.\nStrategy: Standard Layout.\nInputs: A 'Step Forward (Merge)' button and a 'Reset' button.\nBehavior: Display three main sections vertically or in a clean grid: 1. 'Current Corpus State' showing the words, their counts, and how they are currently split into tokens. 2. 'Top Pair Frequencies' showing the most frequent adjacent token pairs in the current state. 3. 'Learned Merge Rules' (Vocabulary additions). \nWhen 'Step Forward' is clicked: \n1. Automatically find the most frequent adjacent pair across the whole corpus (e.g., in step 1, 'e' and 'r' appear 6 times in 'newer' and 3 times in 'wider', totaling 9). \n2. Visually highlight these tokens being merged. \n3. Update the 'Current Corpus State' to show the merged token (e.g., 'n e w er _'). \n4. Add the rule (e.g., 'e + r -> er') to the 'Learned Merge Rules' list. \nContinue this process on subsequent clicks, dynamically recalculating pair frequencies. Provide clear visual cues linking the top pair to the corpus update.","id":"im_f256beb209ae530d"}}
4. Cross-Lingual Generalization and Vocabulary Scaling
The data-driven nature of BPE allows it to generalize across morphological boundaries without explicit linguistic rules:
- Morphological Robustness: Common words (e.g.,
the) are merged into single tokens, whereas rare words (e.g.,postmodernism) are decomposed into known sub-components (post,modern,ism). This ensures that the model can handle any input string by reverting to character-level tokens as a fail-safe. - Multilingual Density: Modern tokenizers utilize massive BPE vocabularies (often exceeding tokens) to support high-fidelity translations across dozens of languages simultaneously, ensuring that non-English text is not unfairly penalized by excessive sequence lengths.
5. Architectural Conclusions
Byte Pair Encoding shifting the paradigm from rule-based linguistics to statistical informatics. By optimizing the tokenization process for information density rather than human syntax, BPE provides the foundational stability required for LLMs to achieve high-order reasoning across diverse datasets.
[!NOTE] Research Insight: While BPE is highly effective, the choice of vocabulary size involves a critical trade-off: a larger reduces sequence length and increases inference speed but increases the parameter count in the model's embedding and softmax layers.